Cloud environments call for dynamic and flexible computing, meaning that fleets of virtual machines can be scaled up and down depending on the load. These machines need a consistent, repeatable and standardized way of setting the startup images and its configuration for the applications that run on them. Pre-built virtual machine images, containing the configuration and software needed are a perfect fit to solve these needs and they are known as Golden images. Golden images save time and help easing deployments and enforcing security and compliance policies. Furthermore, they help reducing errors, as manual configuration is reduced, and in some cases not even needed.

Data center by Cisco
In this post, two tools which are used to build golden images are reviewed using practical examples: AWS Image Builder and Packer. You can find the code used for these examples in this repository.
AWS Image Builder
This tool was recently (December 2019) launched by AWS. It helps automating the management and build of Amazon Machine Images (AMIs) within the AWS ecosystem, as it is integrated with some other AWS services.
AWS Image Builder offers a pretty intuitive graphic interface, although it can be also handled by means of the AWS CLI and CloudFormation (AWS’s IaC) for automation purposes. However, the different components that make it work haven’t been implemented in Terraform yet.
Building a simple AMI
In order to create a new AMI, the first step will be to create a recipe. As its name suggests, a recipe contains all the elements (components) needed to build an AMI. In the image below, a recipe configuration is shown. The source image can be either an AWS managed image, or a custom AMI. The latter requires the systems manager (SSM) agent to be previously installed in the source image. The source image version can be specified, unless we want to build always the latest available version, In that case, semantic versioning is used.
Once the source image and its version has been selected, it’s time to select the components that will be applied to the image during the building phase. As for the images, both pre existing components and self-developed components can be selected. AWS offer a set of prebuilt components, which are managed by them and perform usual tasks, such as rebooting the instance or installing python, so browse them before you start implementing a specific component, you may save some time!
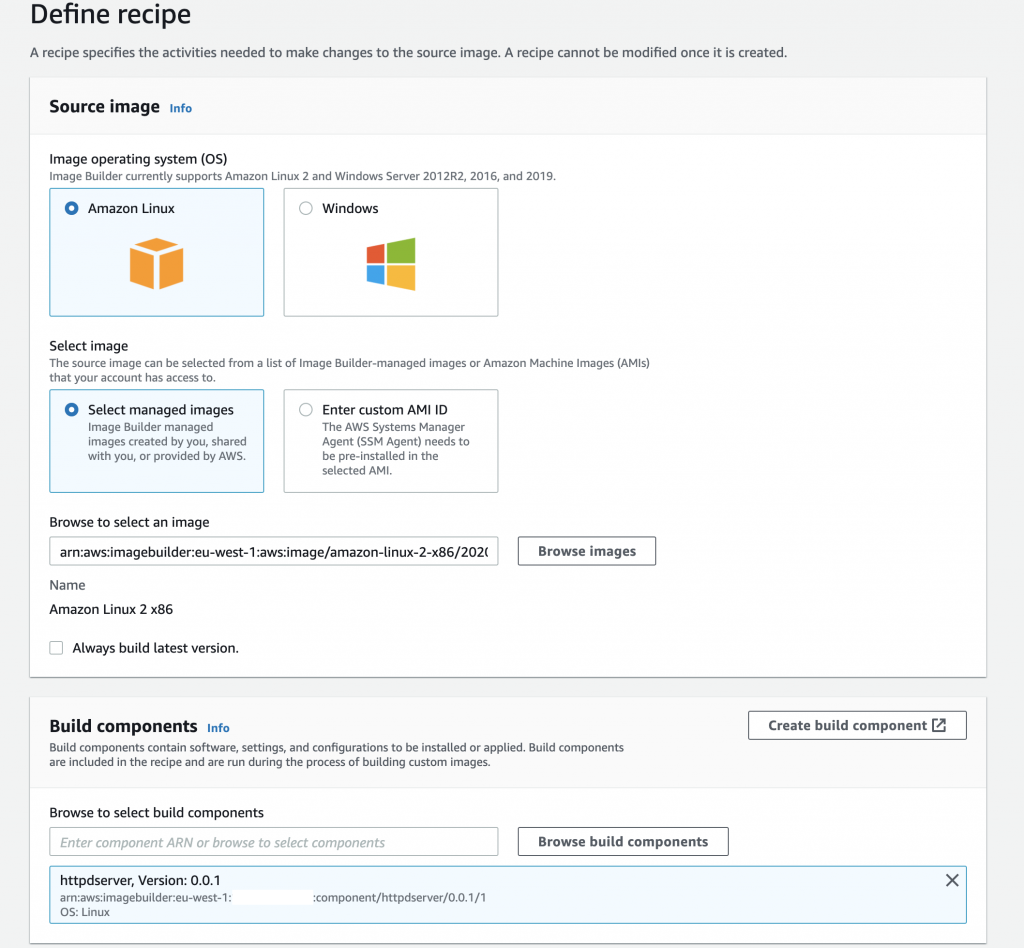
Recipe Configuration
When creating a component, you must specify its name and version. Optional descriptions can be added in order to better understand what’s added into the image with this component. Components can be optionally encrypted using KMS keys. A component is defined as a yaml file, where the different phases for the building process are specified.
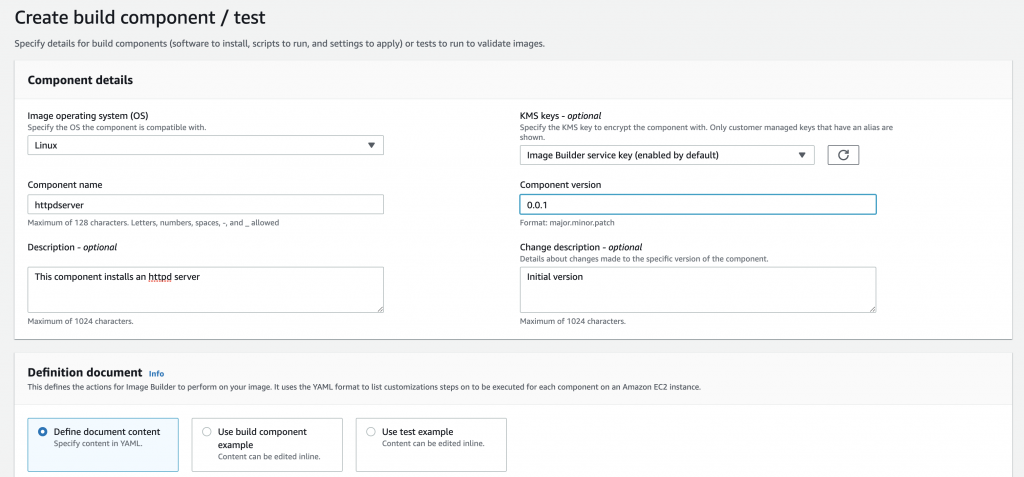
Component configuration
Within each phase, several steps can be defined. Each step has to have a unique name, and all steps are executed sequentially. In the code snippet below a pretty simple component document is shown. It installs a httpd server and sets it to run on boot. Besides, it fetches a customized index page for the server from a s3 bucket.
name: AMIBuilderDocument
description: This document builds an AMI
schemaVersion: 1.0
phases:
- name: build
steps:
- name: Echo-some-text
action: ExecuteBash
inputs:
commands:
- 'echo "Building an AMI for Kubes & Clouds!"'
- name: Update-yum
action: ExecuteBash
inputs:
commands:
- 'yum update'
- name: Install-httpd
action: ExecuteBash
inputs:
commands:
- 'yum -y install httpd'
- name: enable-httpd
action: ExecuteBash
inputs:
commands:
- 'systemctl enable httpd'
- name: Download
action: S3Download
onFailure: Continue
inputs:
- source: s3://your-bucket-name-here/index.html
destination: /var/www/html/index.html
- name: test
steps:
- name: curl-httpd
action: ExecuteBash
inputs:
commands:
- 'curl localhost'
A test phase can be defined within the same component or using the test tab in the recipe creation dashboard. The test phase will deploy a different instance to carry out the tests defined.
However, more advanced configurations can be used in the documents. The inputs and outputs from different steps can be chained to pass arguments and variables between these steps. In the code snippet below, an application is retrieved from a s3 bucket, by using the S3Download action and installed, taking advantage from input/output chaining.
name: LinuxBin
description: Download and execute a custom Linux binary file.
schemaVersion: 1.0
phases:
- name: build
steps:
- name: Download
action: S3Download
inputs:
- source: s3://mybucket/myapplication
destination: /tmp/myapplication
- name: Enable
action: ExecuteBash
onFailure: Continue
inputs:
commands:
- 'chmod u+x '
- name: Install
action: ExecuteBinary
onFailure: Continue
inputs:
path: ''
arguments:
- '--install'
- name: Delete
action: ExecuteBash
inputs:
commands:
- 'rm '
Once the recipe and its components are ready, it’s time to set the builder pipeline up. Builds can be scheduled by using CRON expressions or a job scheduler if needed, otherwise, they will be launched by hand.
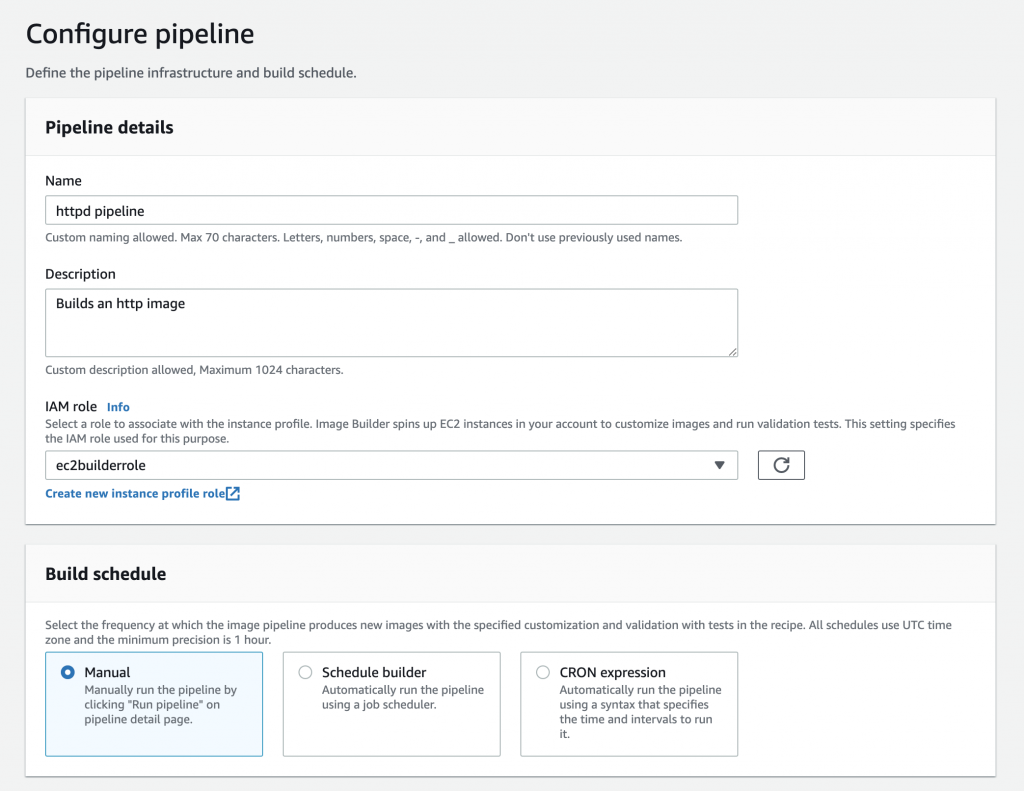
At this point, you might be wondering: how does AWS build an AMI? The same way you would do it! 😆The Image Builder service launches an EC2 instance in which the recipe is applied and then the output AMI is created from this instance. If tests are to be performed, a test instance is deployed too. Thus, these instances need to have access to some of the AWS services, including the Systems Manager service which is used to establish a connection to the instances and run the commands defined within each component.
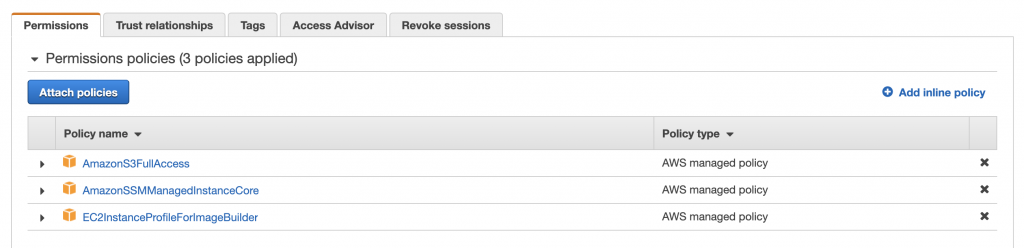
That’s why you’re asked for an IAM role when configuring the pipeline. This role will be associated to the instance profile used by the building and testing instances. Thus, you will have to create a role for that purpose, but don’t worry, it’s an easy task.
Using the IAM console, select the option create role. You will only have to attach three AWS managed policies to this role: AmazonS3FullAccess, AmazonSSMManagedInstanceCore and EC2InstanceProfileForImageBuilder. These policies are developed and managed by AWS, and ensure access to the services needed for the instances. The first one ensures that the build and test instances have access to the S3 buckets of the account, and the other ones allow Image Builder to communicate with the intermediate instances.
Once the roles are ready, the next step will be configuring the instance type to use as well as some optional infrastructure settings. SNS topics can be configured to send information and alerts from the Image Builder service. Furthermore, a S3 bucket can be configured to dump there the output logs generated during the building and test phases. A key par can be also specified to access the image via SSH if needed. All of these options are perfect for troubleshooting purposes. Instance networking settings can be configured in this step too.
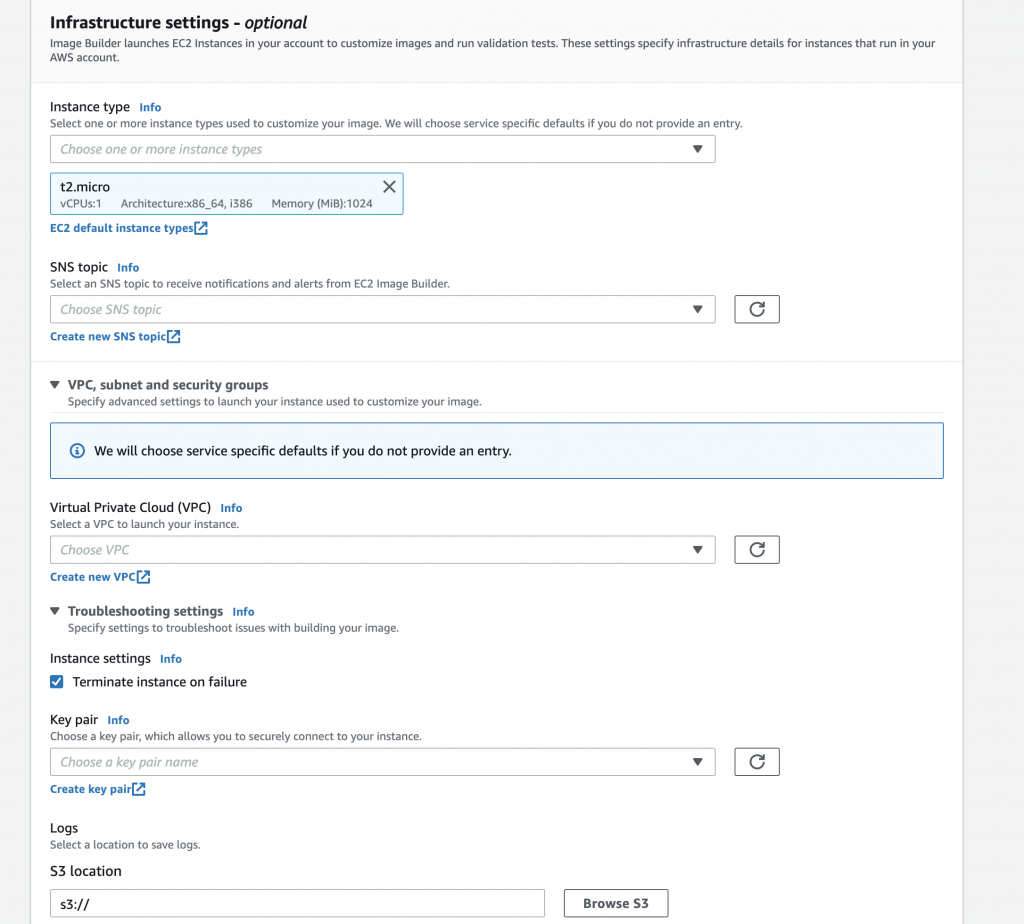
Finally, the output AMI name needs to be specified, and it can be tagged with the key-value pairs you may need for your particular scenario. The region or regions to which the image can be distributed as well as the launch permissions are specified in this final step.
Now that everything is set, it’s time to launch the pipeline, and wait for it to complete⌛☕.
Once the image has been built, it can be used to launch an instance. Select the newly created AMI, configure and launch a new instance and wait until the instance is available.

When the instance is up and running, note down its public IP address to access the web server, but first, you will need to open HTTP traffic in the inbound rules of the security group the instance is associated to. Notice that port 22 was already configured to allow SSH connections. Since it is a test, just allow you own public IP.

The public IP address of the instance can be obtained in the EC2 dashboard, by selecting the instance, in the description tab.

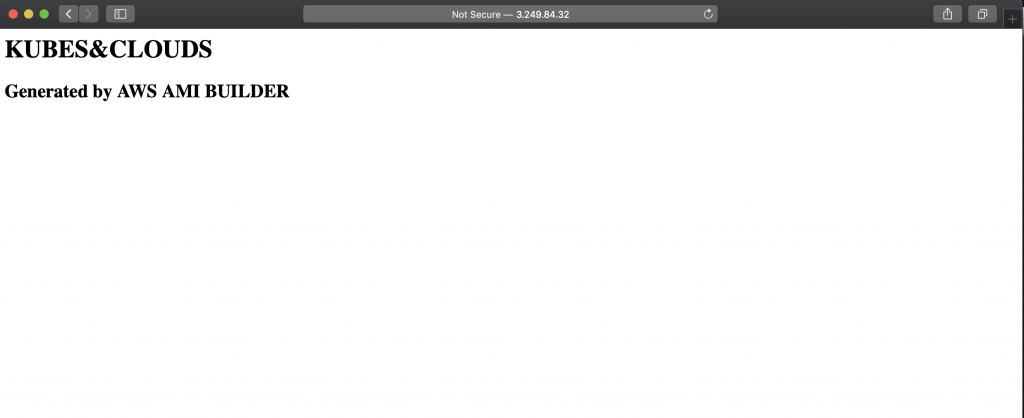
And voilà, by accessing the public IP of the new instance, the custom page downloaded from the S3 bucket is shown.
Finally, we can check the logs generated during the build and testing process in the s3 bucket that was designated for that purpose. Each phase (build,test) generates a new directory (with a rather complex and long suffix), with two folders. The most useful information can be found in the one which starts with ‘TOE’ and is followed by a timestamp. This directory contains the entire log of the phase, the console output, the yaml document of the specific component as well as json outputs.
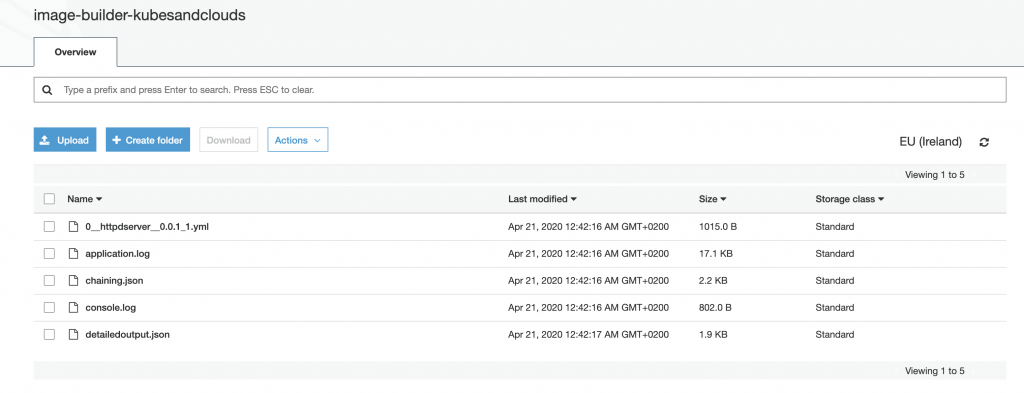
The image below, shows the console.log of the test phase. As you can notice, it worked as expected.

Packer
Packer is an open source tool created by Hashicorp (creators of Terraform, Vault, Vagrant and some other lovely DevOps tools). It allows to create virtual machine images in different platforms by using the same configuration files.
Packer is distributed as a lightweight binary (unless you want to compile it from source), and it’s controlled using its CLI. Packer follow the instructions specified in the json configuration files and builds AMIs by the interacting with the AWS API, that’s why it needs access credentials. It works in a pretty similar fashion as Image Builder does, however its behavior can be customized by using different builders. For our example we will use the amazon-ebs builder, which launches an ebs-backed image, runs the commands specified to Packer and finally creates a new AMI. If you want to know more about the different types of builders and its strategies, you can check them out here.
Getting Packer
First, get the precompiled version of Packer for your operating system. Once you’ve gotten it, it’s time to decompress the file and place it within your PATH, so that it can invoked from the command line.
unzip packer_1.5.5_darwin_amd64.zip
mv packer /usr/bin
packer --version
Building a simple AMI
Now that Packer is installed, it’s time to create a configuration file. Packer uses json templates. The template below constructs the same httpd AMI that was built by using AWS Image Builder, but in this case, it uses a different index page. Notice the two variables defined, they will contain the credentials used to access AWS. Both are passed to Packer when invoking it, keeping them away from the code. As commented before, the amazon-ebs builder is used here, specifying the AWS region, source AMI, instance name and some additional parameters. Finally, shell provisioners are used to execute the same commands to install httpd.
Besides, this document incorporates an inline policy document, which defines the policy needed by the intermediate builder machine to access the s3 bucket where the html file is located.
{
"variables": {
"aws_access_key": "",
"aws_secret_key": ""
},
"builders": [{
"type": "amazon-ebs",
"access_key": "",
"secret_key": "",
"region": "eu-west-1",
"source_ami": "ami-06ce3edf0cff21f07",
"instance_type": "t2.micro",
"ssh_username": "ec2-user",
"ami_name": "httpd ",
"temporary_iam_instance_profile_policy_document": {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:Get*",
"s3:List*"
],
"Resource": "*"
}]
}
}],
"provisioners": [
{
"type": "shell",
"inline": [
"echo 'Building an AMI for Kubes & Clouds!'"
]
},
{
"type": "shell",
"inline": [
"sudo yum update && sudo yum -y install httpd"
]
},
{
"type": "shell",
"inline": [
"sudo aws s3 cp s3://your-bucket-name-here/index_packer.html /var/www/html/index.html"
]
},
{
"type": "shell",
"inline": [
"sudo systemctl enable httpd"
]
}
]
}
As commented, Packer make calls to the AWS API, so you will need to create an user with the adequate permissions for it to work. As it will only need to use the API, this user is configured with a programmatic access. By doing this, two keys (access key and secret key) are provided so that Packer can be authenticated and authorized when using AWS API.
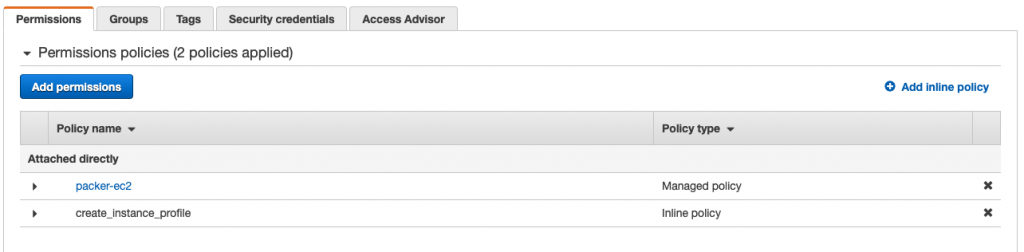
Packer provides an AWS policy which sets up the minimal set of permissions for Packer to build images. Furthermore, in order to use a temporary instance profile, this policy must be included. Just choose ‘create policy’ and paste the policy into the json policy editor for each one of the policies.
Once you’ve completed this steps, you will be able to get your access key and secret key. Store them properly since it is the only time AWS will provide you with this keys, if you lose them, there is no way you can get them back!
Now that everything is ready, is time to invoke Packer. By issuing the command below, Packer will build an image following the specifications defined in the json file.
packer build -var 'aws_access_key=YOURKEY' -var 'aws_secret_key=YOURSECRET' httpd.json
Packer shows a pretty detailed output of what’s being done in during the build process, which can be specially useful for debugging purposes.
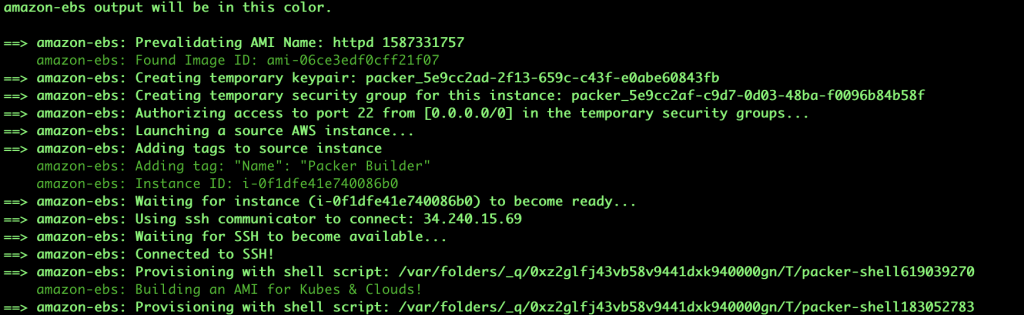
Packer uses an intermediate instance to build the final AMI. If you check the instances page during the build process, you will be able to see the instance running.
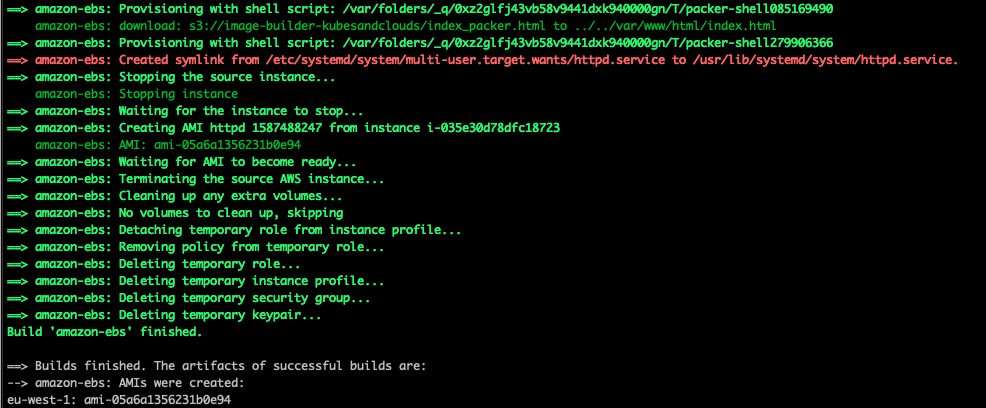
Once Packer has finished building the AMI, it outputs the AMI ID, and it is ready to be used.

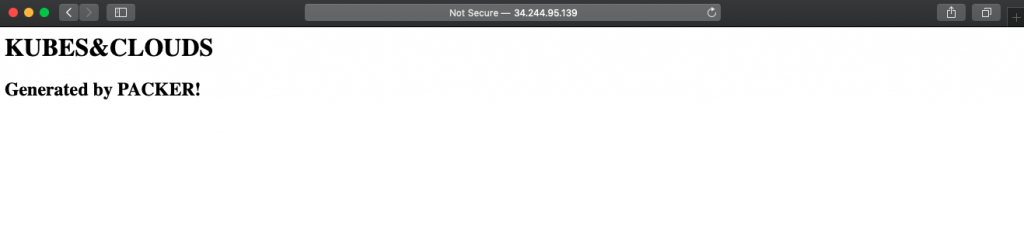
Let’s launch an instance using the newly created AMI. Once it’s up & running, it’s time to check if everything went as expected. Remember to open port 80 in the security group of the instance, otherwise, the web server wouldn’t be able to be accessed.

And once more, it worked as expected! Our httpd server is running and displaying the customized page.
Making it more interesting
The examples above were a good starting point but they were too simple. Combining Image Builder and Packer with some other tools is what really unleashes their potential. In the next examples, both image building tools are combined with a pretty powerful configuration management and deployment tool: Ansible.
Packer and Ansible
Packer support Ansible as an integrated provisioner, so playbooks can be directly referenced in the Packer file. For this example, an Debian 10 source AMI is used, and a Jenkins automation server is installed on top of it. For this image, files are organized following the structure you can see here.
The Ansible provisioner uses two parameters here; the path of the playbook file and the requirements file, which holds the roles that our playbook will use to install Jenkins. In this implementation, tags are used to better identify the output AMI.
{
"variables": {
"aws_access_key": "",
"aws_secret_key": ""
},
"builders": [{
"type": "amazon-ebs",
"access_key": "",
"secret_key": "",
"region": "eu-west-1",
"source_ami": "ami-006d280940ad4a96c",
"instance_type": "t2.micro",
"ssh_username": "admin",
"ami_name": "jenkins ",
"tags": {
"sourceamiid": "",
"sourceami": "",
"owner": "kubes&clouds"
}
}],
"provisioners": [
{
"type": "shell",
"inline": [
"echo 'Building a Jenkins AMI for Kubes & Clouds!'"
]
},
{
"type": "ansible",
"playbook_file": "./ansible/jenkins.yml",
"galaxy_file": "./ansible/requirements.yml"
}
]
}
Two Ansible roles are used in this case, geerlingguy.java and geerlingguy.jenkins. The first one installs the desired java version and the second one installs and tests Jenkins. Both work on RHEL/CentOS and Debian/Ubuntu images, detecting automatically the distribution type.
- hosts: all
become: true
vars:
jenkins_hostname: localhost
java_packages:
- openjdk-11-jdk
pre_tasks:
- name: Install gpg
apt:
name: gpg
roles:
- role: geerlingguy.java
- role: geerlingguy.jenkins
tasks:
- name: Install some more pkgs
apt:
name:
- unzip
- curl
The requirements.yml file contains the URL of each one of the Github repos where the roles are located. Ansible Galaxy is used by Packer to fetch the roles before executing the Ansible playbook.
# External Jenkins role
- name: geerlingguy.jenkins
src: git+https://github.com/geerlingguy/ansible-role-jenkins
- name: geerlingguy.java
src: git+https://github.com/geerlingguy/ansible-role-java
Once the image is successfully built, it can be tested by launching a new instance. Notice that in this case, Jenkins use the port 8080 by default, although it can be modified by changing the variables of the Ansible role.
AWS Image Builder and Ansible
The same process can be replicated using AWS Image Builder. In this case, and to try another Linux distribution, Ubuntu 18.0 LTS was used for the recipe.
The following component is a part of the recipe to build the Jenkins server with Ansible. In this case, the playbook files are obtained from a S3 bucket for simplicity, but in a real environment, they might be located in a remote code repository. Ansible is not supported as an action in components, so in order to make it work, it needs to be installed first, alongside its dependencies.
name: JenkinsComponent
description: This component builds a Jenkins server using Ansible
schemaVersion: 1.0
phases:
- name: build
steps:
- name: InstallAnsible
action: ExecuteBash
inputs:
commands:
- 'sudo apt update'
- 'sudo apt install software-properties-common -y'
- 'sudo apt-add-repository --yes --update ppa:ansible/ansible'
- 'sudo apt install ansible -y'
- name: MakeDir
action: ExecuteBash
inputs:
commands:
- 'sudo mkdir /home/ansible'
- name: DownloadPlaybook
action: S3Download
onFailure: Abort
inputs:
- source: s3://your-bucket-name-here/jenkins.yml
destination: /home/ansible/jenkins.yml
- name: DownloadRequirements
action: S3Download
onFailure: Abort
inputs:
- source: s3://your-bucket-name-here/requirements.yml
destination: /home/ansible/requirements.yml
- name: ExecutePlaybook
action: ExecuteBash
inputs:
commands:
- 'cd /home/ansible'
- 'ansible-galaxy install -r requirements.yml'
- 'ansible-playbook jenkins.yml'
- name: test
steps:
- name: TestJenkins
action: ExecuteBash
inputs:
commands:
- 'curl localhost:8080'
It is interesting to notice here that AWS Image Builder can be managed by means of the CLI, which makes automation easier. However, keep in mind that several files (one for each component, pipeline or recipe) and several CLI calls are needed to set up and run a pipeline. Furthermore, some elements, like pipelines require the ARNs of the other ones, so they must be created in a specific order, and the ARNs returned by the CLI must be stored.
The code snippets below, show the component, recipe, infrastructure, distribution configuration and pipeline objects respectively. Notice that the component definition yaml file was previously updated to a S3 bucket.
{
"name": "InstallJenkins",
"semanticVersion": "0.0.1",
"description": "An example component that installs Jenkins",
"changeDescription": "Initial version.",
"platform": "Linux",
"uri": "s3://your-bucket-name-here/component.yaml",
"tags": {
"owner": "kubesandclouds"
}
}
{
"name": "JenkinsRecipe",
"description": "An example recipe that installs Jenkins.",
"semanticVersion": "1.0.0",
"components": [
{
"componentArn": "you-component-arn-here"
}
],
"parentImage": "your-source-ami-arn-here"
}
{
"name": "MyExampleInfrastructure",
"description": "Infrastructure for Jenkins Build",
"instanceTypes": [
"t2.micro"
],
"instanceProfileName": "ec2builderrole",
"logging": {
"s3Logs": {
"s3BucketName": "your-bucket-name-here",
"s3KeyPrefix": "/"
}
},
"terminateInstanceOnFailure": true
}
{
"name": "MyExampleDistribution",
"description": "Copies AMI to eu-west-1",
"distributions": [
{
"region": "eu-west-1",
"amiDistributionConfiguration": {
"name": "Jenkins ",
"amiTags": {
"owner": "kubes&clouds"
}
}
}
]
}
{
"name": "MyJenkinsPipeline",
"description": "Builds Jenkins images",
"imageRecipeArn": "your-recipe-arn-here",
"infrastructureConfigurationArn": "your-infrastructure-config-arn-here",
"distributionConfigurationArn": "your-distribution-config-arn-here",
"imageTestsConfiguration": {
"imageTestsEnabled": true,
"timeoutMinutes": 60
},
"status": "ENABLED"
}
Once you have your json files ready, each piece can be created by means of AWS CLI. Remember that you will need the ARN from previous objects, so follow the exact same order, and paste the obtained ARNs in your files.
aws imagebuilder create-component --cli-input-json file://component.json
aws imagebuilder create-image-recipe --cli-input-json file://recipe.json
aws imagebuilder create-distribution-configuration --cli-input-json file://configuration.json
aws imagebuilder create-infrastructure-configuration --cli-input-json file://configuration.json
aws imagebuilder create-image-pipeline --cli-input-json file://pipeline.json
As in the previous example, you can launch an instance to check whether the AMI was successfully built. In this case, you can check the Ubuntu distribution by accessing Jenkins system properties.

If you want to know more about Image Builder and its integration with the AWS CLI check this documentation.
Conclusion
In this post two Image Builder tools for AWS AMIs were reviewed, using some examples to better illustrate how they work and the advantages provided by each approach.
Both tools offer a CLI, easing its automation and its usage form CI/CD pipelines, which can be an added value for some environments, as for example, pushing a new version of the code can trigger AMI builds for testing and deployment purposes.
Although they work in a similar manner, it’s clear that currently, Packer is a more advanced tool than AWS Image builder, as it has been in the market for a longer time. Packer offers different builders and it can be used on several cloud platforms, making easier image portability across these platforms. Besides, it offers several provisioners, such as Ansible, Chef and Puppet that are already integrated within the tool, removing the need for downloading and configuring additional software. However, AWS Image Builder offers some interesting integrations with AWS resources, which may help reducing configuration tasks.
From the logging and debugging point of view, I find Packer simpler, as the output is directly shown in the command line as the image is built, rather than having to inspect specific folders in your bucket.
In conclusion, Packer is a more stable and proven tool, probably because it is older, but AWS Image Builder is well integrated with the AWS ecosystem, and I am pretty sure it will continue evolving to offer more integrations and utilities.